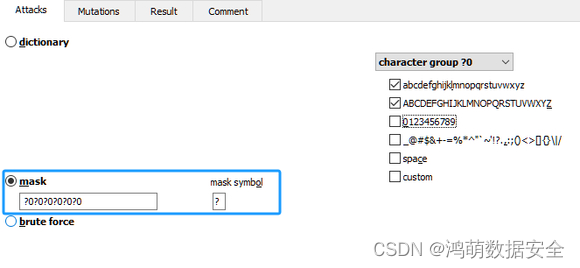
1. jieba分词
import jieba
text='在中国古代文化中,书法和绘画是艺术的重要表现形式。古人常说,‘文字如其人’,通过墨迹可以窥见作者的性情和气质。而画家则以笔墨搏击,表现出山川河流、花鸟虫鱼的灵动。这些艺术形式不仅仅是技艺的表现,更是一种精神的抒发和文化的传承。'
# 分词
words = jieba.cut(text,cut_all=False)
print(list(words))
返回结果:
['在', '中国', '古代', '文化', '中', ',', '书法', '和', '绘画', '是', '艺术', '的', '重要', '表现形式', '。', '古人', '常说', ',', '‘', '文字', '如其人', '’', ',', '通过', '墨迹', '可以', '窥见', '作者', '的', '性情', '和', '气质', '。', '而', '画家', '则', '以', '笔墨', '搏击', ',', '表现', '出', '山川', '河流', '、', '花鸟虫鱼', '的', '灵动', '。', '这些', '艺术', '形式', '不仅仅', '是', '技艺', '的', '表现', ',', '更是', '一种', '精神', '的', '抒发', '和', '文化', '的', '传承', '。']
2. spaCy的中文模型进行分词
import spacy_stanza
import stanza
# 下载并加载 Stanza 中文模型
stanza.download('zh')
nlp = spacy_stanza.load_pipeline('zh')
text='在中国古代文化中,书法和绘画是艺术的重要表现形式。古人常说,‘文字如其人’,通过墨迹可以窥见作者的性情和气质。而画家则以笔墨搏击,表现出山川河流、花鸟虫鱼的灵动。这些艺术形式不仅仅是技艺的表现,更是一种精神的抒发和文化的传承。'
doc = nlp(text)
words = [token.text for token in doc]
print(words)返回结果:
['在', '中国', '古代', '文化', '中', ',', '书法', '和', '绘画', '是', '艺术', '的', '重要', '表现', '形式', '。', '古', '人', '常', '说', ',', '‘', '文字', '如', '其', '人', '’', ',', '通过', '墨迹', '可以', '窥见', '作者', '的', '性情', '和', '气质', '。', '而', '画家', '则', '以', '笔', '墨', '搏击', ',', '表现', '出', '山川', '河流', '、', '花鸟', '虫', '鱼', '的', '灵动', '。', '这些', '艺术', '形式', '不', '仅仅', '是', '技艺', '的', '表现', ',', '更是', '一', '种', '精神', '的', '抒发', '和', '文化', '的', '传承', '。']
3. 分析和比较
-
第一段分词结果:
- 将一些词语合并成了一个词组,如 "表现形式"、"古人"、"笔墨"、"花鸟虫鱼"。
- 分词结果更加符合语言习惯和表达习惯,一些固定搭配和成语被识别并合并成一个词组。
- 可能更适合一些语义理解或者对上下文整体理解较为重要的应用场景。
- 第二段分词结果:
- 每个词都单独分开,保留了原文中的每个词语。
- 分词粒度较细,适合某些需要对每个词语进行精确处理的场合。
4. 选择合适的分词结果
选择哪种分词结果取决于你的具体需求:
- 如果需要对每个词语进行单独处理,或者进行详细的语言分析,第二段分词结果更适合。
- 如果需要更符合日常语言使用习惯的分词结果,或者进行更高层次的语义理解,第一段分词结果可能更适合。
5. spaCy分词方式的一些补充
import spacy
nlp = spacy.load("zh_core_web_sm")
doc = nlp(text)
print([w.text for w in doc])上面这也是spaCy的一种实现中文文本处理的方式,但是它和spacy_stanza与什么区别吗?
下面来讲一下,它们的区别:
这两种中文文本处理方式的主要区别在于使用的底层技术和处理能力。
5.1 使用 spacy_stanza 集成的 Stanza 中文模型
- 底层技术:Stanza 是由斯坦福大学开发的,使用的是基于神经网络的深度学习模型,提供了更高精度的 NLP 处理能力。
- 模型大小:Stanza 的模型通常较大,需要更多的计算资源,但提供了更高的精度。
- 处理能力:在中文分词、词性标注、依存句法分析和命名实体识别等方面通常表现更好,特别适合需要高精度分析的任务。
- 性能:由于模型更大且计算复杂度更高,加载和处理速度较慢,适用于需要高精度分析的批量处理任务。
5.2 使用 spaCy 的中文模型 zh_core_web_sm
- 底层技术:spaCy 使用的是自己的 NLP 模型和算法。
- 模型大小:
zh_core_web_sm是一个小型模型,主要适用于基础的 NLP 任务。 - 处理能力:可以进行词性标注、依存句法分析、命名实体识别等基本 NLP 任务,但在中文分词和处理复杂句法方面可能不如 Stanza 精确。
- 性能:加载和处理速度较快,适用于轻量级和实时的 NLP 任务。